UniMC: Taming Diffusion Transformer for Unified Keypoint-Guided Multi-Class Image Generation

Although significant advancements have been achieved in the progress of keypoint-guided Text-to-Image diffusion models, existing mainstream keypoint-guided models encounter challenges in controlling the generation of more general non-rigid objects beyond humans (e.g., animals). Moreover, it is difficult to generate multiple overlapping humans and animals based on keypoint controls solely. These challenges arise from two main aspects: the inherent limitations of existing controllable methods and the lack of suitable datasets. First, we design a DiT-based framework, named UniMC, to explore unifying controllable multi-class image generation. UniMC integrates instance- and keypoint-level conditions into compact tokens, incorporating attributes such as class, bounding box, and keypoint coordinates. This approach overcomes the limitations of previous methods that struggled to distinguish instances and classes due to their reliance on skeleton images as conditions. Second, we propose HAIG-2.9M, a large-scale, high-quality, and diverse dataset designed for keypoint-guided human and animal image generation. HAIG-2.9M includes 786K images with 2.9M instances. This dataset features extensive annotations such as keypoints, bounding boxes, and fine-grained captions for both humans and animals, along with rigorous manual inspection to ensure annotation accuracy. Extensive experiments demonstrate the high quality of HAIG-2.9M and the effectiveness of UniMC, particularly in heavy occlusions and multi-class scenarios.
The generation of non-rigid objects, such as humans and animals, is vital across various domains. While previous works on keypoint-guided human image generation have utilized skeleton images as structural conditions, it is difficult for those methods to generate multi-class, multi-instance images of humans and/or animals, especially in scenarios with overlapping instances. This is due to limitations in both the conditional formulation (class and instance binding confusion) and the available datasets. Most methods plot keypoints on images as control signals, which leads to ambiguity. For example, it's hard to distinguish if keypoints should depict a cat or a dog, and challenging to determine which keypoint belongs to which instance in overlapping regions. Furthermore, existing datasets are often limited to humans or animals separately and lack the quality and scale needed for modern generative models.

Skeleton image conditions face two main issues: (a) Class binding confusion and (b) Instance binding confusion.
To overcome the limitations of existing datasets, we introduce HAIG-2.9M. It includes 786K images with an average aesthetic score of 5.91, covering 31 species classes, and annotated with 2.9M instance-level bounding boxes, keypoints, and captions, averaging 3.66 instances per image. To ensure data quality and diversity, we sourced images from high-quality non-commercial websites and filtered large-scale datasets. We then used state-of-the-art models for annotation, with rigorous manual checks to ensure accuracy.
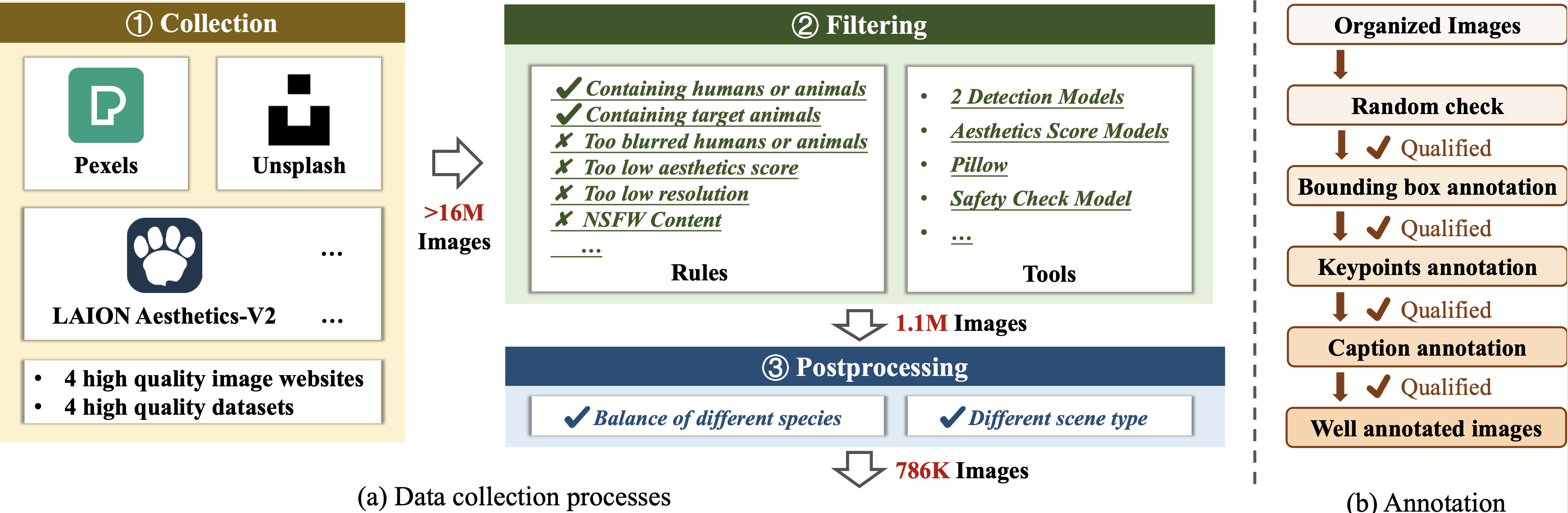
Our dataset collection and annotation pipeline ensures high quality and diversity.
To achieve unified human and animal generation, we present UniMC, a Diffusion Transformer (DiT)-based framework. Instead of skeleton images, we use compact and informative conditions: the keypoint coordinates, bounding box coordinates, and class names for each instance. This allows for class- and instance-aware unified encoding, avoiding the confusion issues of previous methods.
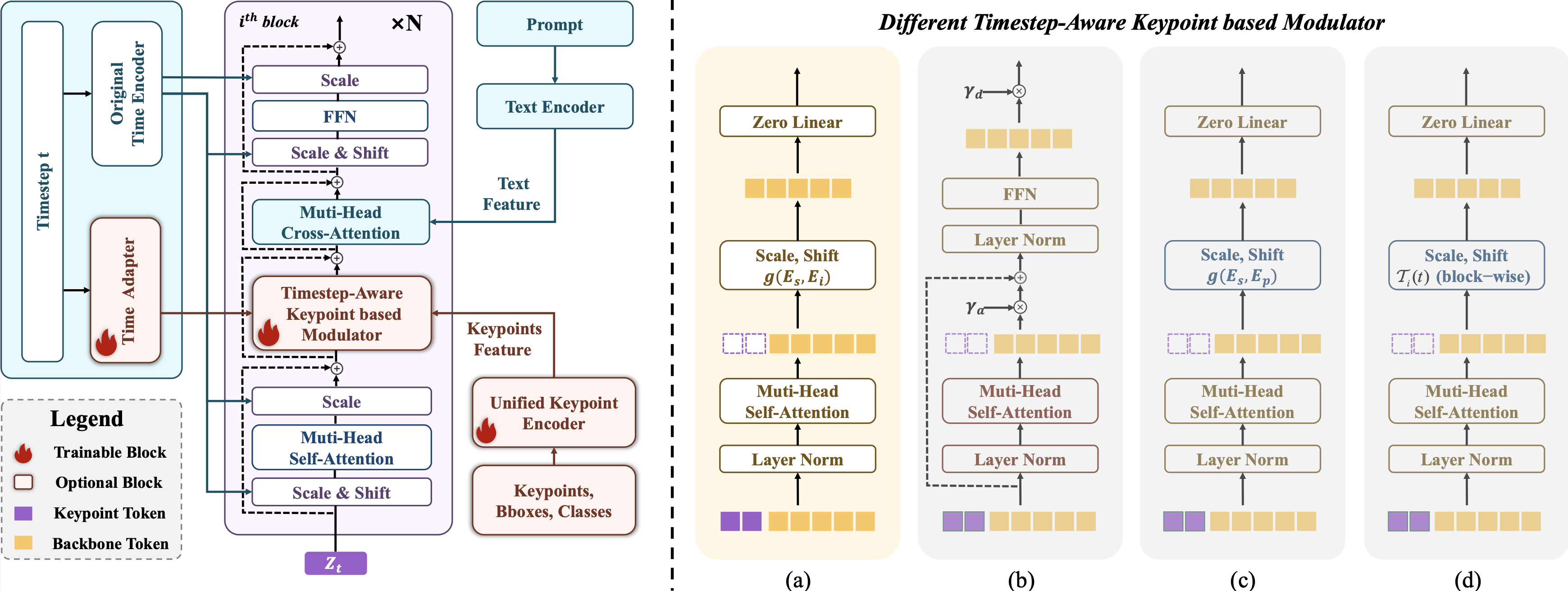
Our framework consists of two key components:
1. Unified Keypoint Encoder: A lightweight module that encodes keypoints and attributes (class, bounding box) from different species into a unified representation space. This addresses the semantic and structural differences across classes and avoids the need for separate encoders. Invisible or missing parts are handled using a learnable mask token.
2. Timestep-aware Keypoint Modulator: We insert self-attention layers into the blocks of the DiT backbone (PixArt-α) to model the relationship between the unified keypoint tokens and the backbone feature tokens. This modulator is designed to be aware of both the image structure and the diffusion timestep, enabling effective keypoint-level control throughout the generation process.
We compare UniMC with representative methods like the base PixArt-α model, ControlNet (using skeleton images), and GLIGEN (using keypoint coordinates). Our qualitative and quantitative results demonstrate the superiority of UniMC. It achieves fine-grained control of poses for different classes and instances while maintaining high-quality generation, even in challenging scenarios with heavy occlusion. The results also highlight the importance of our HAIG-2.9M dataset; models trained on it significantly outperform those trained on combined existing datasets like COCO and APT36K.

Qualitative Comparisons: UniMC (b) successfully generates complex, multi-class scenes with accurate poses, outperforming ControlNet (f) and GLIGEN (g), and showing the benefit of the HAIG-2.9M dataset over COCO (c), APT36K (d), or their combination (e).
This paper presents work whose goal is to advance the field of Machine Learning. Our model enhances creativity with precise keypoint-level control but carries misuse risks. We emphasize responsible use and transparency.
@inproceedings{guo2025unimc,
title={Uni{MC}: Taming Diffusion Transformer for Unified Keypoint-Guided Multi-Class Image Generation},
author={Qin Guo and Ailing Zeng and Dongxu Yue and Ceyuan Yang and Yang Cao and Hanzhong Guo and Fei Shen and Wei Liu and Xihui Liu and Dan Xu},
booktitle={Forty-second International Conference on Machine Learning},
year={2025}
}